看到Ilya Grigorik写的这篇高性能网络技术实践 后,一直想找个机会好好阅读一下。之前遇到英文文章的话我还是喜欢偷个懒,直接找中文版本。借这个机会,第一次体会翻译英文文章。全书免费线上阅读 ,准备细细地读一下。
Google Chrome的历史和指南 在2008的下半年,Chrome的Beta版本的登陆Windows平台。于此同时,Google将Chrome的核心代码以BSD许可开源,并称其为Chromium。对于关注它的人来说,这一事件引发了一个惊喜的猜想:浏览器大战再燃?Google真的可以做得更好吗?
它体验实在太好了,这让我改变了我最初的想法。抵触想法 的
现在看来,Chrome团队做到了。现在Chrome是全球最广泛使用的浏览器之一(依据StatCounter的统计,超过35% 的市场占有率),并提供了Windows、Linux、OS X 桌面平台版本和Android、iOS移动平台版本。显然,解决了用户痛点的特性与功能,和众多的创新点让Chrome跻身流行浏览器排行。
这本38页的漫画书 详细阐述了Chrome中创新的想法,这提供了一个绝佳的视角,供大家学习开发Chrome过程中思考和设计过程。不过这仅仅只是开始。驱动Chrome开发的核心原则并未改变,依旧是现在Chrome优化的指南:
速度(Speed) :目标就是要做出最快 的浏览器安全(Security) :为用户提供最安全 的使用环境稳定(Stability) :提供稳定而有弹性 的Web应用平台简洁(Simplicity):用复杂的技术驱动起上层简单的用户体验
据团队观察,很多我们现在使用的网站不是简简单单的网页了,而是应用。这样看来,越来越多野心勃勃的应用都把速度、安全、稳定和简洁作为追求,而对于每一个最求,都需要单独成文来说,本文的主题是高性能,所以主要讨论速度。
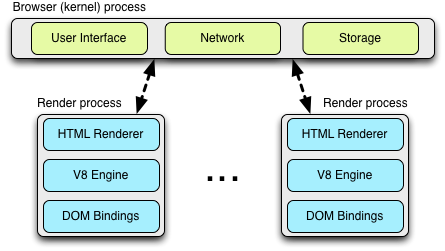
从多个方面来看高性能 现代浏览器是一个平台,就像操作系统一样,Chrome就是照此标准设计的。在Chrome之前,所有主流的浏览器都是单进程应用。所有打开的网页共用一个内存区域,并相互争夺共享的资源。任何页面中或是浏览器中的Bug,都带来了牺牲全局体验的风险。
而Chrome另辟蹊径,工作在一个多进程的模式下。它提供了进程和内存隔离,并将每一个页面运行在安全的沙箱 环境中。在目前多核处理器流行的背景下,隔离进程和保护页面不受恶意网页攻击被证明是Chrome在激烈竞争中的很好抓手。值得注意的是,很多浏览器也迁移到了这一多进程的架构,或是正在迁移之中。
在多进程环境启动后,Web应用的执行主要包含一下三个任务:获取资源、页面布局与渲染、Javascript执行。渲染和脚本执行依照一个单线程、交叉执行的模型——这是由于不能对DOM进行并发修改,这也是Javascript自身单线程的特性造成的。因此,对于Web应用开发者和浏览器开发者,怎样在运行时协同优化渲染和脚本执行是关键一环。
Chrome使用Blink 作为渲染引擎,它也是为速度而生,是一个开源的、标准支持良好的布局引擎。对于Javascript,Chrome推出了精心优化过的Javascript运行环境,V8 ),V8也独立作为项目开源,得到了广泛的使用,例如它也是Node.js的运行环境。不过,如果是浏览器阻塞在网络IO上,针对V8虚拟机优化,或者是对Blink解析和渲染流水线的优化不会产生很好的效果,因为大部分时间还是消耗在了等待网络资源上 。
总用户体验中的最关键因素之一,便是浏览器优化各种网络资源的加载顺序、优先级和延时的能力。你可能都注意不到它,但Chrome的网络栈便是每天逐步演化得更加聪明。它尝试隐去或是降低各种资源加载带来的时延:预先加载最可能的DNS查询、记住网络的拓扑结构、向可能的目标提前发起连接等等。从使用者的角度来看,它只是一个简单的资源加载工具,而从内部来看,它相当精巧和迷人地示范了怎样进行网络性能调优,以及如何带给用户最好的使用体验。
那就让我们一探究竟吧。
现代的Web应用是怎样的? 在我们接触如何对网络进行优化的技术细节之前,理解Web发展潮流和我们需要面对的问题会有所帮助。一个现代的Web页面,或者是一个Web应用究竟是怎样的?
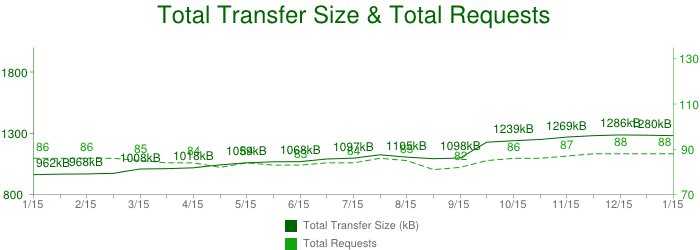
HTTPArchive 项目追踪着互联网是如何构建的,它能帮我们回答这些问题。它周期性地爬取最流行的站点,对它们使用的资源数量、文件类型、headers和各种元数据进行记录和聚合分析,而并不关注站点的内容数据。2013年一月的数据可能会让你惊讶,在最流行的300,000个站点中,平均下来一个网页的数据如下:
大小约为1280KB
共计88个资源文件
共连接了超过15个独立的主机
让我们细细分析一下。平均大于1MB的数据传输,包含88个资源文件如图片、Javascript和CSS,并是从15个独立的主机或第三方主机加载而来!这些数字在过去几年中都在稳定增长 ,现在看来没有减缓停止的趋势。这说明我们在不断开发更大的Web应用。
稍加计算我们发现资源的平均大小是12KB(1045KB/84),这说明浏览器中大多数的网络传输是短小猝发的 。因为使用的底层协议(TCP)是专为较大和流式文件传输优化的,这就带来了一系列并发问题。让我们逐步剥开一个网络Request看看。
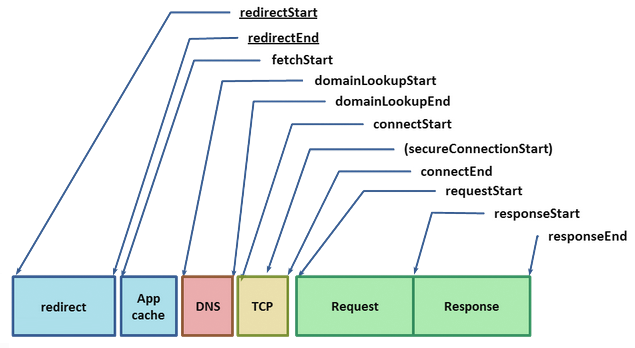
一个Request的一生 W3C Navigation Timing specification 提供了一个浏览器API来展示每一次Request的性能数据。让我们详细观察这些组成部分,因为它们都是优化的用户体验的一个重要组成部分。
给定一个网络资源的URL,浏览器从检查本地caches开始。如果之前已经加载过这份资源并且和cache控制相关的headers 已经被设置(比如Expires, Cache-Control ),接着便可使用本地的拷贝来回应这个Request-最快的Request便是不产生真实的Request 。有时文件过期,我们需要重新让这个文件具有最新的时效,或是之前没有加载过它,那么一个网络Request必须被发出,不过这是代价高昂的。
给定一个Hostname和Resource Path,Chrome先检查是否有打开的连接可以被重用,Sockets以{scheme, host, port}的三元组被池化使用。如果Proxy被设置,或是使用了一个自动Proxy设置脚本(PAC),Chrome会通过合适的Proxy检测连接。PAC脚本允许针对URL路由不同的Proxy,这每一套规则都有其自己的Socket池。最终,如果以上条件都不满足,那么这个Request必须首先将主机名解析为IP地址,即DNS查询开始 。
如果幸运的话,这个Hostname已经被查询过并被缓存,那么我们距离Response就只有一个系统调用的距离了。不是这样的话,那么DNS查询必须完成,之后其他工作才能继续开展。DNS查询的时间依据网络提供商的不同,可能差距很大,比如网站的流行度和本Hostname在中间DNS服务器缓存的可能性,还有对应域名服务器的响应时间,都会影响这一时间消耗。换句话说便是变数很多,而且要知道一个数百毫秒 的DNS查询也不是不常见,真是肉疼。
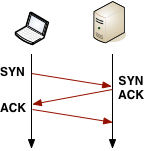
解析好的IP地址到手后,Chrome便可向目标打开一个新的TCP连接,这需要经过三次握手 :SYN > SYN-ARK > ACK。这次数据交换让每个新的TCP连接都背负了一个完整的Roundtrip时延 ,似乎没有捷径可走。依据客户端和服务端的距离与选择的路由路径,这可造成十至百,乃至上千毫秒的延时。这些工作都是在一个有效的Request数据传输前需要消耗的!
一旦TCP握手完成,如果我们是用HTTPS协议建立连接的话,SSL握手又将开始。这又将增加两个Roundtrip时延 ,如果SSL回话被缓存,那么我们可以开心地节省一次Roundtrip。
终于,Chrome可以发送HTTP Request(上图requestStart标识)。服务器收到回复后便处理Request并发送Response。这造成了一个Roundtrip,并加上服务器的处理时间。似乎我们终于结束了,不过如果如果返回了HTTP Redirect,我们还需要再重走一遍。所以如果你服务器上有好几个Redirect,最好优化一下这个实现。
你是不是已经开始计算总的延时了呢?我们在特定的带宽情况下来假设一个延时最大的情况,本地缓存失效,立刻执行一个较快的DNS查询(50ms),TCP握手,SSL握手和一个相对较快的服务器响应时间(100ms),并设定Roundtrip时间为80ms(一个跨越美洲的平均时间)。
50ms DNS查询
80ms TCP握手,(一次RTT)
160ms SSL握手,(两次RTT)
40ms 发送请求给服务器
100ms 服务器处理请求
40ms 服务器返回结果
本单次Request总计470毫秒,其中和真正的服务器处理请求的时间想比,80%的时间消耗在了网络延时上 。我们得做点什么!事实上,470毫秒已经是一个乐观的估计了:
如果服务器的响应不能被装入一个最先的TCP拥塞窗口 (4-15 KB),那么需要继续加上一个或多个Roundtrip延时。
如果我们需要加载一个缺失的证书,或是进行一个在线证书状态检查 (OCSP),SSL延时可能会更长。可能会增加数百上千的毫秒延时。
怎样算是“足够快”? 在我们之前的例子中,由于DNS、握手和Roundtrip造成的延时是影响总延时的大头,其中服务器造成的延时只有区区20%。但是,从更加宏观的角度来看,这个延时有造成影响吗 ?在读本文的你可能已经知道了答案:对,影响很大。
之前的用户体验调查 展示了我们作为用户,对各种应用响应程度的需求:
延时
用户反馈
0 - 100ms
秒开啊
100 - 300ms
似乎顿了一下
300 - 1000ms
好吧还好不是死机
1s+
我刚才想干什么来着
10s+
容我去睡一会
上表也解释了Web性能社区的一个不成文的规定:渲染页面,或者至少在250ms内提供视觉反馈,来保持用户的注意力。这不能算是从源头上提高了速度。Google、Amazon、Microsoft等千家网站都发现额外的延时对网站有着直接影响:更快的网站意味着更多的PV,更高的参与度和更高的转化率。
说到这你应该明白了,我们优化目标是250ms,而上述DNS查询,TCP/SSL握手和Request传输时间加在一起足足由370ms,我们已经超了50%的时间,并且我们甚至还没有考虑服务器的时间消耗!
对于绝大多数用户,甚至开发者而言,DNS、TCP和SSL延时都是完全透明的,并且是在网络层进行的,我们便较少深入和思考。但这些步骤却对总体用户体验有着极大的影响,因为这都可能带来十或百的毫秒延时。这就是为什么Chrome的网络栈比一个简单的Socket处理程序复杂很多的原因 。
现在我们已经认清了问题所在,让我们深入实现细节看看 。
从10,000英尺高度鸟瞰Chrome的网络栈 多进程架构 Chrome的多进程架构明显地暗示了在浏览器中一个网络Request是如何处理的。在底层,Chrome实际上支持四种不同的执行模型 来确定使用哪一种进程分配模型。
默认情况下,桌面版的Chrome使用Process-per-site模型,这将不同网站隔离开来,并将同一网站的所有实例都组在一个进程中。不过,为了更加方便大家理解,让我们假设这样一个简单的情况:对于每一个打开的tab,都分配一个独立的进程。从网络性能角度来考虑,区别不是很大,但Process-per-tab的模型更加容易理解。
这一架构下,每一个渲染进程 都对应与一个tab,其中都运行着开源Blink布局引擎,它是解释和进行HTML布局的(也就是图中的“HTML Renderer”),还运行着V8 Javascript虚拟机、桥接这两个引擎的代码和一些其他组件。如果你感兴趣的话,可以查看Chromium wiki中的介绍 。
每一个这些“render”进程都在沙盒环境下执行,这保证它们对用户电脑的访问受限,当然也包含了网络。为了获取这些资源,每一个render进程和Browser主进程进行通信,这就可以为每一个render加上安全的访问策略。
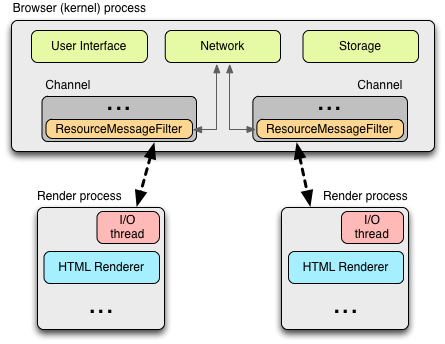
进程内通信(IPC)和多进程资源加载 在Render和Browser进程间的所有通信都是通过IPC完成的。在Linux和OS X中,一个socketpair()用来提供一个异步的、有标识的管道传输。每个来自render的消息都被序列化后,传递给一个专用的I/O线程,由I/O线程再向Browser进程分发。在接收端,Browser进程提供一个过滤器接口,这运行Chrome对资源IPC请求进行拦截处理(查看ResourceMessageFilter ),转交给网络栈进行处理。
一个本架构的好处是所有的资源Request都在I/O线程上处理,所以任何UI触发的活动或是网络事件会不相互干涉。资源过滤器在Browser进程的I/O线程中执行,拦截资源Request消息,并将它们转发给Browser进程中的ResourceDispatcherHost 单实例对象。
单实例接口下,浏览器可控制每个render对网络的访问,这也让一个高效和一致的资源共享机制成为可能。
Socket池和连接数限制 :浏览器可限制打开的sockets数量,默认为256每个profile,32每个Proxy,和6每个{scheme, host, port}三元组。这表明同时最大可以允许6个HTTP和6个HTTPS连接到同一个{host, port}!Socket重用 :TCP连接在为某Request服务后可以不断开,被保存在Socket池中以重用,这也就避免了附加的DNS,TCP和SSL(如果需要的话)重新建立带来的开销。Socket后期绑定 :Requests只有在socket可以传输应用的Request的时候,才和一个底层的TCP连接绑定,这样便可更好进行Request的优先级调度(例如在socket建立连接的时候,产生了更高优先级的Request),更好的吞吐(比如在打开新的连接的时候,已有的socket变为可用状态,便可以重复使用“热”的TCP连接)。同时还有TCP预连接和一系列的其他优化。持续的会话状态 :验证,Cookies和缓存数据可以在所有的render进程间共享。全局资源和网络优化 :可以基于所有的请求进行决策,比如说,给予前台tab的网络请求更高的优先级。基于预测的优化 :通过观察所有的网络流量,Chrome可以建立并改善预测模型来提升性能。还有很多
对于render进程来说,它需要做的仅仅是用一个独特的Request ID来标记一个Request请求消息,并通过IPC发送出去,然后一切交由Browser进程接手。
跨平台的资源获取
在实现Chrome的网络栈中,其中一个主要的关注点便是在多个平台间的可移植性:Linux, Windows, OS X, Chrome OS, Android, 和iOS。为了应对这一挑战,网络栈被实现为通常单线程工作(有分离的缓存和代理线程)的,跨平台的库,这使Chrome可重用相同的基础代码,并提供相同的性能优化,这也是跨平台优化的绝佳机会。
所有相关的网络的代码,都开源在src/net 子目录 。在这我们不会详细讨论所有的模块,但你能从代码的布局看出它的结构和可以跨越的平台。举个例子:
net/android
Android运行时的绑定
net/base
通用网络工具库,例如域名解析,cookies,网络环境变动侦测,SSL证书管理
net/cookies
HTTP cookies的存储、管理和获取的实现
net/disk-cache
网络资源的磁盘和内存的缓存实现
net/dns
一个异步DNS解析器的实现
net/http
HTTP协议的实现
net/proxy
代理(Socks和HTTP)配置,解析,脚本获取等等
net/socket
跨平台的TCP sockets实现,SSL流和Socket池
net/spdy
SPDY协议实现
net/uri_request
URLRequest, URLRequestContext, and URLRequestJob的实现
net/websocket
Websockets协议实现
以上每一个子模块都适合好奇的你阅读,代码文档齐全,并且你会找到不少单元测试。
在移动平台上的架构和性能
即便是谨慎估计,移动浏览器的使用率也呈现出指数级的增长,可以预期在不远的将来,它将蚕食桌面浏览器的份额,令其黯然失色。因此对于Chrome团队,带给用户良好的移动浏览体验是具有极高优先级的。在2012年初,Chrome Android 推出,几个月后,Chrome iOS 也推向市场。
对于Chrome的移动版本,你需要了解的头一件事情便是它不是桌面浏览器的直接移植 ,如果那样将不能获得最好的用户体验。客观来说,移动环境资源更加紧缺,并有着更多不同的操作参数:
桌面用户使用鼠标浏览,可能由重叠的窗口,有很大的显示屏,并且一半没有电池能耗限制,通常有一个稳定的网络连接,并有更大的磁盘存储和内存。
移动用户使用触摸和手势进行浏览,有很小的屏幕,需要考虑能耗,网络连接不畅,只有受限的存储和内存。
更进一步来说,很难说一个设备是典型的“移动设备 ”,反倒是很大量的设备的性能都各不相同,Chrome必须对每个设备都能很好的适应,才能带来最佳的性能。幸运的是,正是因为多种多样的运行模型,Chrome才能做到这种适应性。
在Android设备上,Chrome也使用了和桌面版本相同的多进程架构 ,有一个Browser进程,和一个或多个Renderer进程。唯一的不同便是移动设备的内存容量限制,Chrome不太可能还是采取每个tab一个Renderer的策略。Chrome通过可用的内存,和设备的其他限制条件,来确定最优的Renderer数量。它会在多个tab中分享Renderer进程。
在只有很少的资源可用,或者是Chrome不能启动多进程架构的时候,它还是可以切换到一个单进程多线程的运行模型中。事实上,在iOS设备上,由于底层平台的沙箱限制,Chrome就是这么做的——单进程多线程运行 。
那网络性能呢?首先,在Android和iOS中,Chrome使用了同样的网络栈,其他平台也一样 。这让Chrome可以在多平台下实现相同的网络优化,这对Chrome的性能优化工作来说十分重要。但是,某些参数比如预测优化的优先级、Socket的超时、管理逻辑和缓存大小,在不同平台间还是有所区别的,并随着设备的能力和使用的网络动态调整。
例如,为了节约电池,移动版Chrome有选择地推迟关闭空闲的Socket,仅仅当打开新的Socket后,才会关闭旧的,这样可以最小化发射功率。类似的是,我们上文中提到的预渲染,是需要一笔不菲的网络和处理资源支出的,这通常在用户处于WIFI环境下才会开启。
对于Chrome开发团队来说,优化移动浏览体验是处于最高优先级列表中的一个,可以预见的是,很多新的提升 将不断推出。事实上,这个话题值得单独成文,兴许在POSA系列的下一篇中。
推测式的Chrome预测优化
你越是使用,Chrome越快 。这得归功于Predictor单例对象。它在Browser进程中国被初始化,而它的职责就是观察网络模式,学习并预测用户接下来可能的动作。比如说:
当用户将鼠标置于某一个超链接上时,这说明他接下来可能会导航到那里,Chrome便可以预先开始进行DNS查询,甚至预先进行TCP握手。等当用户真正点击的时候,这通常已经过去了大约200ms,我们很可能已经完成了DNS和TCP阶段,为这次浏览节约了数百毫秒的额外时延。
在Omnibox(URL)中输入时,会根据相似度提示,这也会激活类似的预测优化:DNS查询、TCP预连,甚至可以在后台预先渲染出这个页面。
我们每人都有最爱的一些网站。Chrome可以从这些站点的资源中学习,并预测性地预先解析、获取这些资源来加速浏览体验。
这个列表还能写很长…
Chrome会发现网络的拓扑,并在你使用时学习你独有的浏览习惯。如果一切顺利的话,它将为用户每次浏览节省下数百毫秒的延时,让用户接近“秒开”的畅快体验。为了做到这一点,Chrome利用了四个核心优化技术:
DNS 预解析
提前进行域名解析,来避免DNS延时
TCP 预连接
提前和目标服务器进行连接,来避免TCP握手延时
资源预加载
提前获取关键资源文件,来加速页面的渲染
页面预渲染
提前获取整个页面,包括所有的资源文件,当用户真正点击时,带来秒开的体验
每个优化动作在触发前,都要经过一系列的限制条件,毕竟,这仅仅只是通过预测来优化,如果预测失败的话,不必要的计算和网络浏览就白消耗了,甚至会对用户的实际浏览造成负面的影响。
那Chrome是如何解决这一问题的呢?预测器会处理尽量多的信号,其中包括了用户产生的动作、历史浏览记录和render、网络栈产生的信号 。
和ResourceDispatcherHost,一个负责Chrome内部所有网络活动的实体,不同的是,Predictor对象对Chrome内部的用户和网络创建了一系列过滤器:
IPC管道过滤器,监测Render进程的信号
ConnectInterceptor实体被添加在每一个Request中,这样的话它便可以观察流量模式,并为每个Request记录下数据(success metrics)。
举个栗子来说,Render进程在如下情况发生时,都会向Browser进程发送消息。请查看在ResolutionMotivation(url_info.h )的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum ResolutionMotivation { MOUSE_OVER_MOTIVATED , // 用户触发的鼠标经过事件Mouse -over initiated by the user. OMNIBOX_MOTIVATED , // Omni -box 提示 STARTUP_LIST_MOTIVATED , // 本资源在10 大最常访问之列 EARLY_LOAD_MOTIVATED , // 某些情况下我们使用预加载来在发射真实的Request 前预热连接 // 如下和预测式预加载有关,由浏览触发 / / The following involve predictive prefetching, triggered by a navigation. STATIC_REFERAL_MOTIVATED, / / 外界知识库 LEARNED_REFERAL_MOTIVATED, / / 从之前的浏览习惯中总结得到 SELF_REFERAL_MOTIVATED, / / 猜测会产生第二次连接 / / <snip> .., }; ```
获知一个信号后,预测器的目标便是评估其正确的可能性,若资源获取到后,激活事件。每个预测都有成功性,优先级和一个有时效的时间戳。组合起来可以建立一个内部的优先队列来优化预测。最终,对于每一个从此队列发出的Request,预测器还会持续追踪它的成功率,这让后续优化成为可能。
果壳中的Chrome网络架构
Chrome使用一个多进程架构 ,这将Render和Browser进程隔离
Chrome维护了一个资源调度分配的单例 ,它被所有Render进程公用,并运行在Browser进程中
网络栈是一个快平台 ,大多数情况下单线程的库
网络栈使用非阻塞 的操作来管理所有的网络操作
共享的网络栈让资源优先级、重用策略更加高效,并让跨进程全局优化成为可能
每个Render进程都和资源分配器通过IPC通信
预测器拦截资源Request和Response,学习并优化未来的Request
预测器会安排DNS,TCP,甚至是资源请求 ,这基于学习到的网络模式,当用户浏览时能节省数百毫秒
(未完待续)